Управление Данными
Развертывания ClickHouse для наблюдаемости неизменно вовлекают большие объемы данных, которые необходимо управлять. ClickHouse предлагает ряд функций для помощи с управлением данными.
Партиции
Партиционирование в ClickHouse позволяет логически разделять данные на диске в зависимости от колонки или SQL-выражения. Разделяя данные логически, каждая партиция может быть обработана независимо, например, удалена. Это позволяет пользователям перемещать партиции, а следовательно, подмножества, между уровнями хранения эффективно и время от времени истекать данные/эффективно удалять из кластера.
Партиционирование задается в таблице при ее первоначальном определении с помощью ключевого слова PARTITION BY. Этот ключ может содержать SQL-выражение на любой колонке/колонках, результаты которого определят, в какую партицию будет отправлена строка.
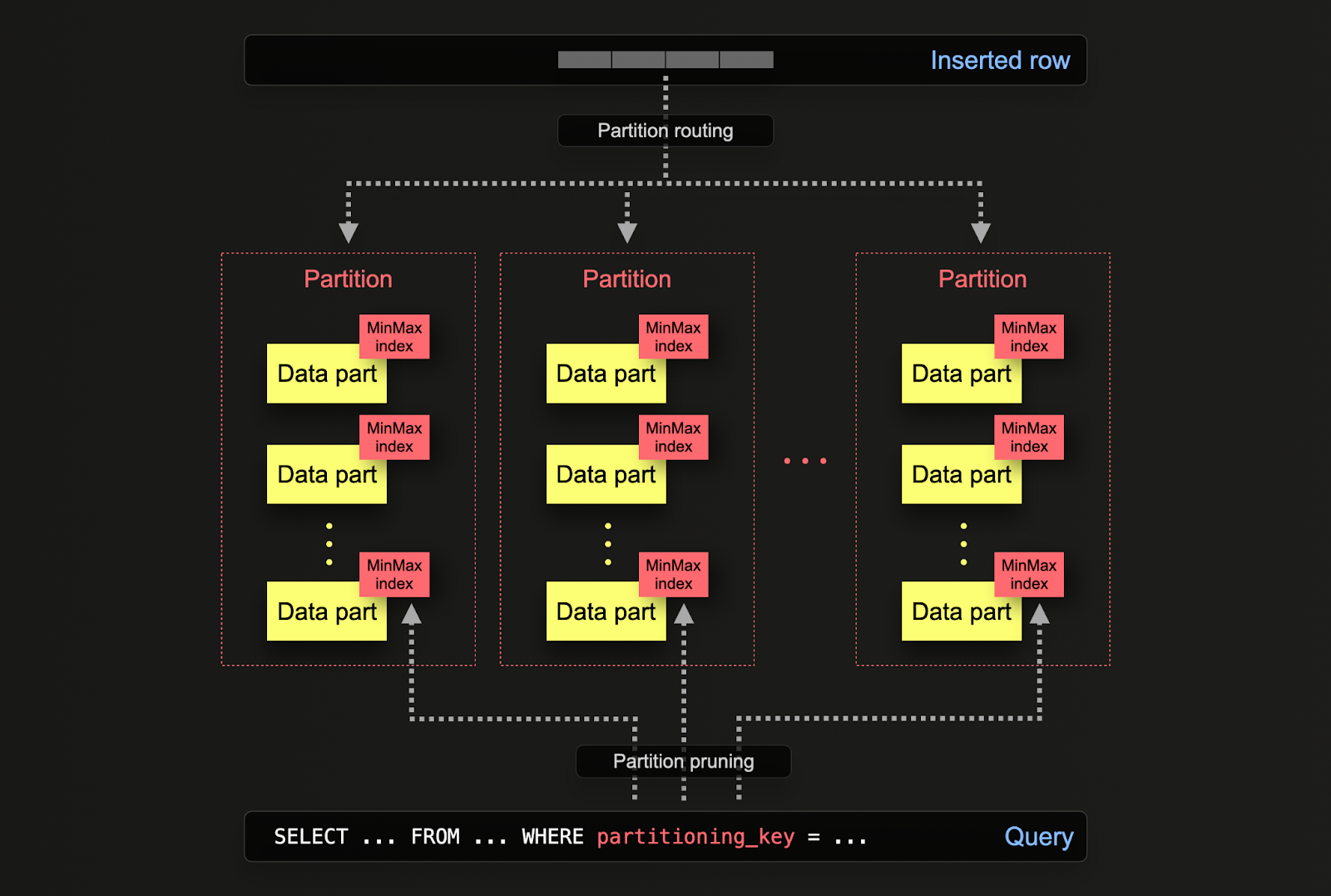
Части данных логически связаны (через общее имя папки-префикса) с каждой партицией на диске и могут быть запрашиваемы в изоляции. Для примера ниже, схема otel_logs по умолчанию партиционируется по дням с использованием выражения toDate(Timestamp). Когда строки вставляются в ClickHouse, это выражение будет оцениваться для каждой строки и направляться в результирующую партицию, если она существует (если строка является первой для дня, партиция будет создана).
На партициях можно выполнить ряд операций, включая резервное копирование, манипуляции с колонками, мутации изменяющие/удаляющие данные по строкам и очистку индексов (например, вторичных индексов).
В качестве примера предположим, что наша таблица otel_logs партиционирована по дням. Если она заполняется структурированным набором логов, она будет содержать несколько дней данных:
Текущие партиции можно найти, используя простой запрос к системной таблице:
У нас может быть другая таблица, otel_logs_archive, которую мы используем для хранения более старых данных. Данные могут быть перемещены в эту таблицу эффективно по партиции (это всего лишь изменение метаданных).
Это в отличие от других методов, которые потребовали бы использование INSERT INTO SELECT и переписывания данных в новую целевую таблицу.
Перемещение партиций между таблицами требует выполнения нескольких условий; не в последнюю очередь таблицы должны иметь одинаковую структуру, ключ партиции, первичный ключ и индексы/проекции. Подробные примечания о том, как задать партиции в DDL ALTER, можно найти здесь.
Кроме того, данные можно эффективно удалять по партициям. Это гораздо более ресурсосберегающий метод, чем альтернативные техники (мутации или легкие удаления) и должен использоваться в первую очередь.
Эта функция используется TTL, когда установка ttl_only_drop_parts=1 включена. См. Управление данными с помощью TTL для получения дополнительной информации.
Применения
Выше показано, как данные могут быть эффективно перемещены и манипулированы по партициям. На практике пользователи, вероятно, чаще всего будут использовать операции с партициями в сценариях наблюдаемости для следующих двух случаев:
- Многоуровневые архитектуры - Перемещение данных между уровнями хранения (см. Уровни хранения), что позволяет строить горячие-холодные архитектуры.
- Эффективное удаление - когда данные достигли указанного TTL (см. Управление данными с помощью TTL)
Мы подробно исследуем оба этих случая ниже.
Производительность запросов
Хотя партиции могут помочь с производительностью запросов, это сильно зависит от схем доступа. Если запросы направлены только на несколько партиций (желательно одну), производительность может улучшиться. Это обычно полезно только в том случае, если ключ партиционирования не входит в первичный ключ и вы фильтруете по нему. Однако запросы, которым необходимо охватить множество партиций, могут работать хуже, чем если бы партиционирование не использовалось (поскольку может быть больше частей). Преимущество нацеливания на одну партицию будет еще менее выраженным или вовсе отсутствующим, если ключ партиционирования уже является ранним элементом в первичном ключе. Партиционирование также может быть использовано для оптимизации запросов GROUP BY, если значения в каждой партиции уникальны. Однако, в общем, пользователи должны убедиться, что первичный ключ оптимизирован, и рассматривать партиционирование как технику оптимизации запросов в исключительных случаях, когда схемы доступа охватывают конкретное предсказуемое подмножество данных, например, партиционирование по дням, с большинством запросов за последний день. См. здесь для примера этого поведения.
Управление данными с помощью TTL (время жизни)
Время жизни (TTL) - это ключевая функция в решениях по наблюдаемости на базе ClickHouse для эффективного хранения и управления данными, особенно учитывая, что огромные объемы данных продолжают генерироваться. Реализация TTL в ClickHouse позволяет автоматическую экспирацию и удаление устаревших данных, гарантируя, что хранилище будет оптимально использоваться и производительность сохраняется без ручного вмешательства. Эта возможность необходима для поддержания базы данных в оптимальном состоянии, снижения затрат на хранение и обеспечения того, чтобы запросы оставались быстрыми и эффективными, сосредотачиваясь на наиболее актуальных и недавних данных. Более того, это помогает в соблюдении политики хранения данных, систематически управляя жизненными циклами данных, тем самым повышая общую устойчивость и масштабируемость решения для наблюдаемости.
TTL можно задать как на уровне таблицы, так и на уровне колонки в ClickHouse.
Уровень таблицы TTL
Схема по умолчанию как для логов, так и для трассировок включает TTL, чтобы истекать данные по истечению определенного времени. Это указывается в экспортере ClickHouse под ключом ttl, например:
Этот синтаксис в настоящее время поддерживает синтаксис длительности Golang. Мы рекомендуем пользователям использовать h и убедиться, что это совпадает с периодом партиционирования. Например, если вы партиционируете по дням, убедитесь, что это кратно дням, т.е. 24h, 48h, 72h. Это автоматически обеспечит добавление условия TTL к таблице, например, если ttl: 96h.
По умолчанию данные с истекшим TTL удаляются, когда ClickHouse объединяет части данных. Когда ClickHouse обнаруживает, что данные истекли, он выполняет внеплановое объединение.
TTL не применяются сразу, а скорее по расписанию, как указано выше. Параметр таблицы MergeTree merge_with_ttl_timeout задает минимальную задержку в секундах перед повторным объединением с удалением TTL. Значение по умолчанию - 14400 секунд (4 часа). Но это лишь минимальная задержка, может потребоваться больше времени, чтобы инициировать объединение TTL. Если значение слишком низкое, будет выполнено много внеплановых объединений, которые могут потреблять много ресурсов. Истечение TTL может быть принудительно вызвано с помощью команды ALTER TABLE my_table MATERIALIZE TTL.
Важно: Мы рекомендуем использовать настройку ttl_only_drop_parts=1 ** (применяется по умолчанию). Когда эта настройка включена, ClickHouse удаляет целую часть, когда все строки в ней истекают. Удаление целых частей вместо частичной очистки строк с истекшим TTL (что достигается через ресурсоемкие мутации при ttl_only_drop_parts=0) позволяет иметь более короткие времена merge_with_ttl_timeout и меньший влияние на производительность системы. Если данные партиционированы по тому же единице, на которой вы выполняете истечение TTL, например, по дням, части будут естественным образом содержать только данные из определенного интервала. Это гарантирует, что ttl_only_drop_parts=1 может быть эффективно применен.
Уровень колонки TTL
Вышеупомянутый пример истекает данные на уровне таблицы. Пользователи также могут истекать данные на уровне колонки. По мере старения данных это может использоваться для удаления колонок, значимость которых в расследованиях не оправдывает их дополнительные расходы на хранение. Например, мы рекомендуем сохранить колонку Body на случай, если новая динамическая метаинформация будет добавлена, которая не была извлечена во время вставки, например, новая метка Kubernetes. После периода, например, 1 месяц, может стать очевидно, что эта дополнительная метаинформация не является полезной - таким образом, уменьшая необходимость в сохранении колонки Body.
Ниже мы показываем, как колонка Body может быть удалена через 30 дней.
Указание TTL на уровне колонки требует от пользователей задания своей схемы. Это не может быть задано в OTel collector.
Рекомпрессия данных
Хотя мы обычно рекомендуем ZSTD(1) для наборов данных наблюдаемости, пользователи могут экспериментировать с различными алгоритмами сжатия или более высокими уровнями сжатия, например, с ZSTD(3). Кроме того, возможность указать это при создании схемы, сжатие может быть настроено для изменения после установленного периода. Это может быть уместно, если кодек или алгоритм сжатия улучшает сжатие, но ухудшает производительность запросов. Этот компромисс может быть приемлем для старых данных, которые запрашиваются реже, но не для недавних данных, которые подвержены более частому использованию в расследованиях.
Пример этого показан ниже, когда мы сжимаем данные с помощью ZSTD(3) после 4 дней вместо удаления их.
Мы рекомендуем пользователям всегда оценивать как вставку, так и влияние производительности запросов различных уровней и алгоритмов сжатия. Например, дельта-кодеки могут быть полезными в сжатии временных меток. Однако, если они являются частью первичного ключа, то производительность фильтрации может пострадать.
Дополнительные сведения и примеры настройки TTL можно найти здесь. Примеры того, как TTL могут быть добавлены и изменены для таблиц и колонок, можно найти здесь. Информацию о том, как TTL позволяют создавать иерархии хранения, такие как горячие-теплые архитектуры, смотрите Уровни хранения.
Уровни хранения
В ClickHouse пользователи могут создавать уровни хранения на разных дисках, например, горячие/недавние данные на SSD и более старые данные, поддерживаемые S3. Эта архитектура позволяет использовать менее дорогое хранилище для более старых данных, у которых более высокие требования к SLA запросов из-за их редкого использования в расследованиях.
ClickHouse Cloud использует единую копию данных, которая поддерживается на S3, с кэшами узлов, поддерживаемыми SSD. Уровни хранения в ClickHouse Cloud, таким образом, не требуются.
Создание уровней хранения требует от пользователей создания дисков, которые затем используются для формулирования политики хранения, с объемами, которые могут быть указаны во время создания таблицы. Данные могут автоматически перемещаться между дисками на основе уровня заполнения, размеров частей и приоритетов объемов. Дополнительные сведения можно найти здесь.
Хотя данные могут быть вручную перемещены между дисками с помощью команды ALTER TABLE MOVE PARTITION, движение данных между объемами также может контролироваться с помощью TTL. Полный пример можно найти здесь.
Управление изменениями схемы
Схемы логов и трассировок неизменно будут изменяться на протяжении жизни системы, например, когда пользователи мониторят новые системы, имеющие различную метаинформацию или метки пода. Создавая данные с использованием схемы OTel и захватывая оригинальные данные событий в структурированном формате, схемы ClickHouse будут устойчивы к этим изменениям. Однако, когда новая метаинформация становится доступной, и схемы доступа к запросам меняются, пользователи захотят обновить схемы в соответствии с этими изменениями.
Чтобы избежать простоя во время изменений схемы, у пользователей есть несколько вариантов, которые мы представляем ниже.
Использование значений по умолчанию
Колонки могут быть добавлены в схему с использованием DEFAULT значений. Указанное значение по умолчанию будет использоваться, если оно не указано во время вставки.
Изменения схемы могут быть внесены до изменения любой логики трансформации представления или конфигурации OTel collector, что приводит к тому, что эти новые колонки будут отправлены.
После изменения схемы пользователи могут перенастроить OTel collectors. Предполагая, что пользователи используют рекомендованный процесс, изложенный в "Извлечение структуры с помощью SQL", где OTel collectors отправляют свои данные в Null таблицу с представлением, ответственным за извлечение целевой схемы и отправку результатов в целевую таблицу для хранения, представление может быть изменено с помощью синтаксиса ALTER TABLE ... MODIFY QUERY. Предположим, у нас есть целевая таблица ниже с соответствующим материализованным представлением (аналогичным тому, что использовалось в "Извлечение структуры с помощью SQL") для извлечения целевой схемы из структурированных логов OTel:
Предположим, мы желаем извлечь новую колонку Size из LogAttributes. Мы можем добавить это в нашу схему с помощью ALTER TABLE, указав значение по умолчанию:
В приведенном выше примере мы указываем значение по умолчанию как ключ size в LogAttributes (это будет 0, если он не существует). Это означает, что запросы, которые обращаются к этой колонке для строк, не имеющих вставленного значения, должны обращаться к Map и, следовательно, будут медленнее. Мы также можем легко указать это как константу, например, 0, что уменьшит стоимость последующих запросов к строкам, у которых нет значения. Запрос к этой таблице показывает, что значение заполняется, как и ожидалось, из Map:
Чтобы гарантировать, что это значение будет вставлено для всех будущих данных, мы можем изменить наше материализованное представление с помощью синтаксиса ALTER TABLE, как показано ниже:
Последующие строки будут иметь колонку Size, заполненную во время вставки.
Создание новых таблиц
В качестве альтернативы вышеописанному процессу пользователи могут просто создать новую целевую таблицу с новой схемой. Все материализованные представления могут быть изменены, чтобы использовать новую таблицу с помощью ALTER TABLE MODIFY QUERY. С этим подходом пользователи могут версионировать свои таблицы, например, otel_logs_v3.
Этот подход оставляет пользователям несколько таблиц для запроса. Чтобы выполнять запросы по этим таблицам, пользователи могут использовать функцию merge, которая принимает шаблоны подстановки для имени таблицы. Мы демонстрируем это ниже, запрашивая v2 и v3 таблицы otel_logs:
Если пользователи хотят избежать использования функции merge и предоставить таблицу конечным пользователям, которая объединяет несколько таблиц, можно использовать табличный движок Merge. Мы демонстрируем это ниже:
Это можно обновить всякий раз, когда новая таблица добавляется с помощью синтаксиса таблицы EXCHANGE. Например, чтобы добавить таблицу v4, мы можем создать новую таблицу и атомарно обменять ее с предыдущей версией.