Параллельные Реплики
Введение
ClickHouse обрабатывает запросы чрезвычайно быстро, но как эти запросы распределяются и параллелизируются на нескольких серверах?
В этом руководстве мы сначала обсудим, как ClickHouse распределяет запрос на несколько шардов через распределенные таблицы, а затем, как запрос может использовать несколько реплик для его выполнения.
Шардированная архитектура
В архитектуре с полным разделением ресурса кластеры обычно разделены на несколько шардов, каждый из которых содержит подмножество общих данных. Распределенная таблица располагается поверх этих шардов, предоставляя унифицированный вид на полные данные.
Чтения могут быть направлены к локальной таблице. Выполнение запроса происходит только на указанном шарде, или он может быть направлен к распределенной таблице, и в этом случае каждый шард выполнит заданные запросы. Сервер, на котором был запрошен доступ к распределенной таблице, агрегирует данные и отвечает клиенту:
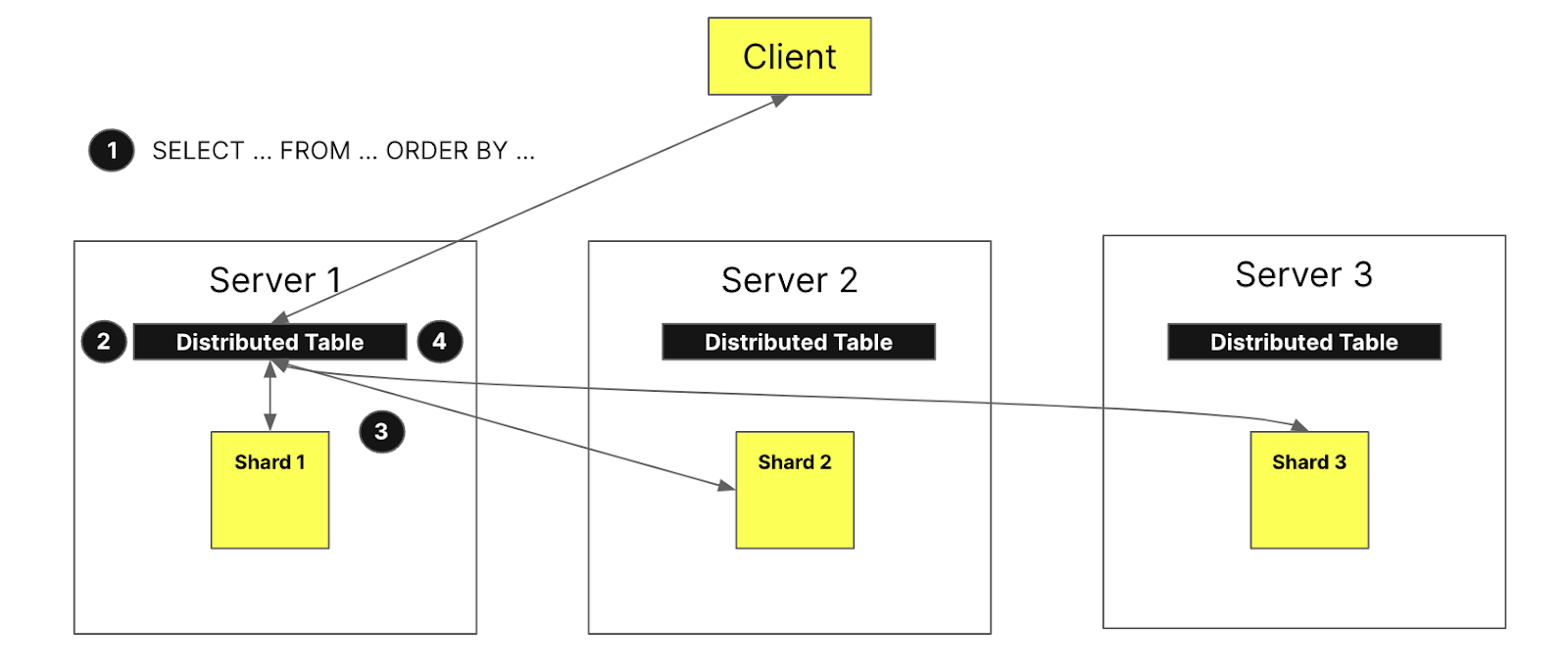
На рисунке выше визуализируется, что происходит, когда клиент запрашивает распределенную таблицу:
Запрос select отправляется к распределенной таблице на узле произвольно (по стратегии round-robin или после маршрутизации к конкретному серверу балансировщиком нагрузки). Этот узел теперь будет выступать в роли координатора.
Узел находит каждый шард, который должен выполнить запрос, с помощью информации, указанной в распределенной таблице, и запрос отправляется на каждый шард.
Каждый шард считывает, фильтрует и агрегирует данные локально, а затем отправляет обратно агрегированное состояние координатору.
Координирующий узел объединяет данные и затем отправляет ответ обратно клиенту.
Когда мы добавляем реплики в процесс, процесс довольно похож, с единственным отличием, что только одна реплика из каждого шарда будет выполнять запрос. Это означает, что больше запросов может быть обработано параллельно.
Не шардированная архитектура
ClickHouse Cloud имеет совершенно другую архитектуру, чем та, что представлена выше. (Смотрите "Архитектура ClickHouse Cloud" для получения более подробной информации). С разделением вычислений и хранения, и с практически бесконечным количеством хранилища, потребность в шардах становится менее важной.
На рисунке ниже показана архитектура ClickHouse Cloud:
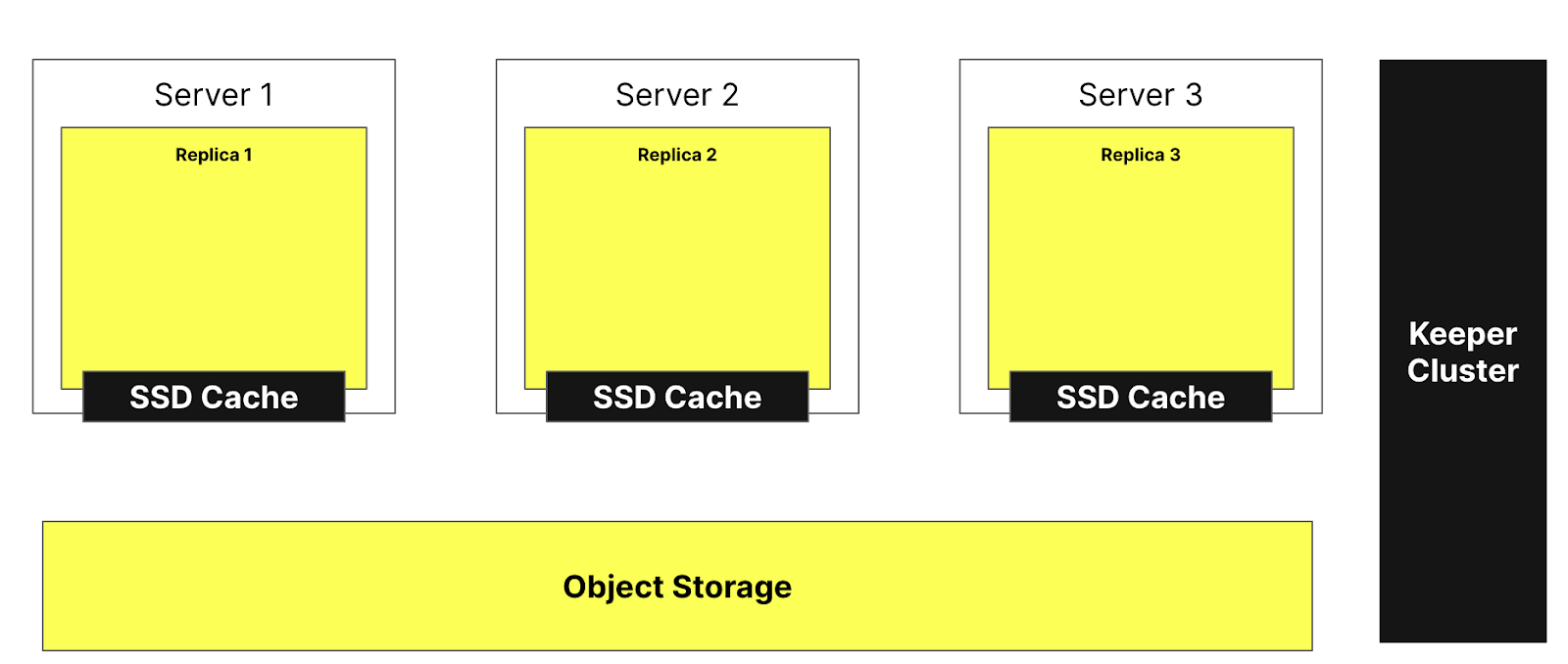
Эта архитектура позволяет нам добавлять и удалять реплики практически мгновенно, обеспечивая очень высокую масштабируемость кластера. Кластер ClickHouse Keeper (показан справа) обеспечивает наличие единого источника правды для метаданных. Реплики могут получать метаданные из кластера ClickHouse Keeper и все поддерживают одни и те же данные. Сами данные хранятся в объектном хранилище, а кэш SSD позволяет нам ускорить запросы.
Но как мы теперь можем распределить выполнение запретов между несколькими серверами? В шардированной архитектуре это было довольно очевидно, так как каждый шард мог фактически выполнить запрос на подмножестве данных. Как это работает, когда нет шардирования?
Введение параллельных реплик
Чтобы параллелизовать выполнение запроса через несколько серверов, нам сначала нужно назначить один из наших серверов координатором. Координатор — это тот, кто создает список задач, которые необходимо выполнить, обеспечивает их выполнение, агрегирует их и возвращает результат клиенту. Как и в большинстве распределенных систем, эту роль исполняет узел, который получает первоначальный запрос. Нам также нужно определить единицу работы. В шардированной архитектуре единицей работы является шард, подмножество данных. С параллельными репликами мы будем использовать небольшую долю таблицы, называемую гранулами, в качестве единицы работы.
Теперь давайте посмотрим, как это работает на практике с помощью рисунка ниже:
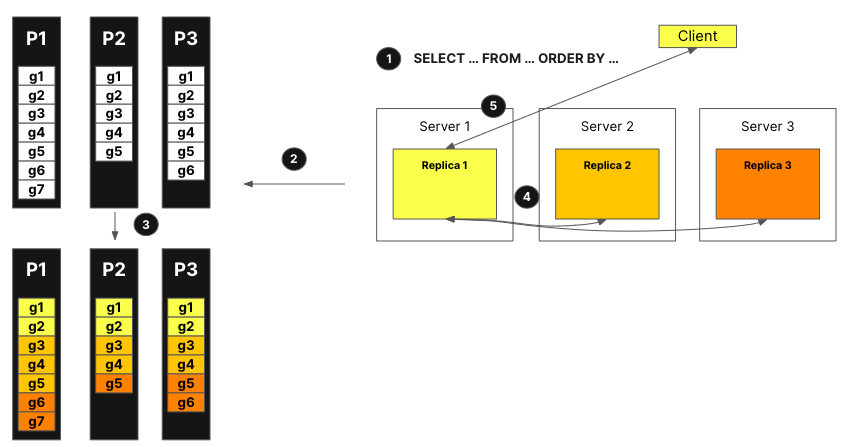
С параллельными репликами:
Запрос от клиента отправляется к одному узлу после прохождения через балансировщик нагрузки. Этот узел становится координатором для этого запроса.
Узел анализирует индекс каждой части и выбирает правильные части и гранулы для обработки.
Координатор делит нагрузку на набор гранул, которые могут быть назначены различным репликам.
Каждый набор гранул обрабатывается соответствующими репликами, и агрегируемое состояние отправляется координатору по завершении.
Наконец, координатор объединяет все результаты от реплик и затем возвращает ответ клиенту.
Шаги выше описывают, как работают параллельные реплики в теории. Однако на практике есть множество факторов, которые могут помешать такой логике работать идеально:
Некоторые реплики могут быть недоступны.
Репликация в ClickHouse асинхронна, некоторые реплики могут не иметь одинаковых частей в определенный момент времени.
Задержка между репликами должна как-то обрабатываться.
Кэш файловой системы варьируется от реплики к реплике в зависимости от активности на каждой реплике, что означает, что случайное распределение задач может привести к менее оптимальной производительности с учетом локальности кэша.
Мы рассматриваем, как эти факторы преодолеваются в следующих разделах.
Объявления
Чтобы решить (1) и (2) из списка выше, мы ввели концепцию объявления. Давайте визуализируем, как это работает, используя рисунок ниже:
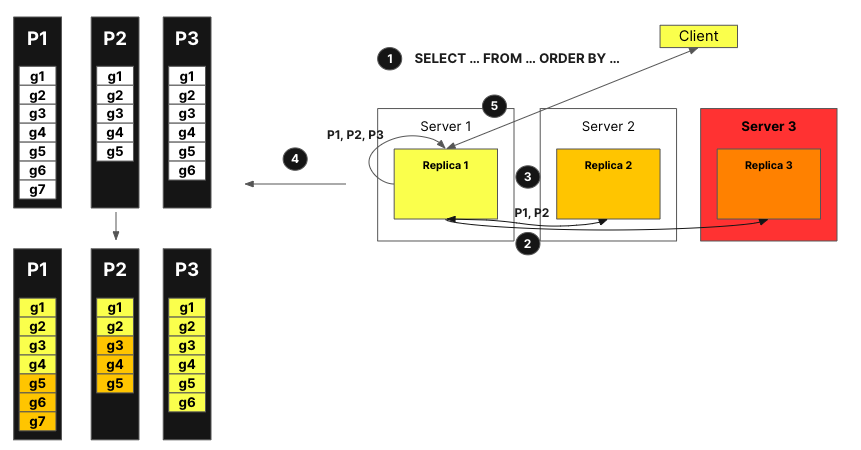
Запрос от клиента отправляется к одному узлу после прохождения через балансировщик нагрузки. Узел становится координатором для этого запроса.
Координирующий узел отправляет запрос для получения объявлений от всех реплик в кластере. Реплики могут иметь слегка разные представления текущего набора частей для таблицы. В результате нам нужно собрать эту информацию, чтобы избежать неправильных решений о расписании.
Координирующий узел затем использует объявления для определения набора гранул, которые могут быть назначены различным репликам. Здесь, например, мы видим, что никакие гранулы из части 3 не были назначены реплике 2, поскольку эта реплика не предоставила эту часть в своем объявлении. Также обратите внимание, что никаких задач не было назначено реплике 3, потому что реплика не предоставила объявления.
После того как каждая реплика обработала запрос на своем подмножестве гранул и агрегируемое состояние было отправлено обратно координатору, координатор объединяет результаты, и ответ отправляется клиенту.
Динамическое координирование
Чтобы решить проблему задержки на конце, мы добавили динамическое координирование. Это означает, что все гранулы не отправляются реплике в одном запросе, а каждая реплика сможет запрашивать новую задачу (набор гранул для обработки) у координатора. Координатор предоставит реплике набор гранул на основе полученного объявления.
Предположим, что мы находимся на этапе в процессе, когда все реплики отправили объявление со всеми частями.
На рисунке ниже визуализируется, как работает динамическое координирование:
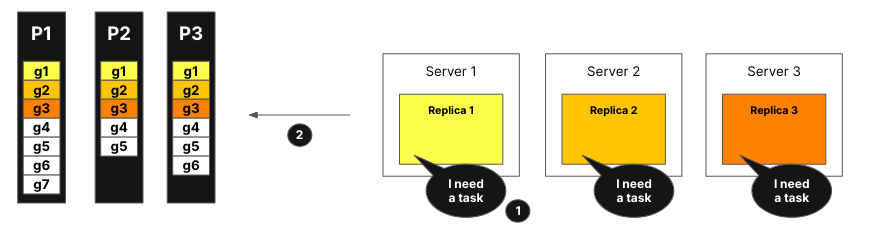
Реплики сообщают координатору, что они могут обрабатывать задачи, они также могут указать, сколько работы могут обработать.
Координатор назначает задачи репликам.
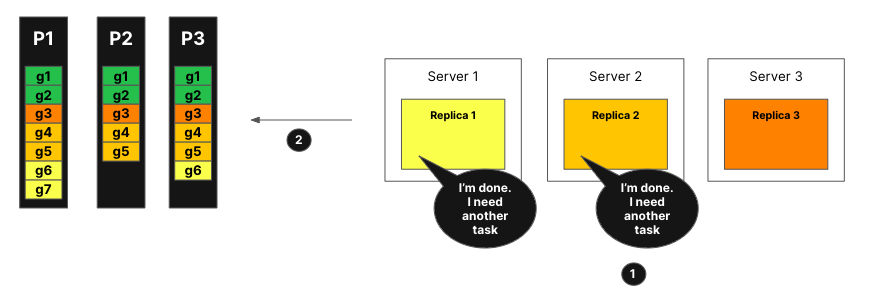
Реплики 1 и 2 могут быстро завершить свою задачу. Они запрашивают новую задачу у координатора.
Координатор назначает новые задачи репликам 1 и 2.
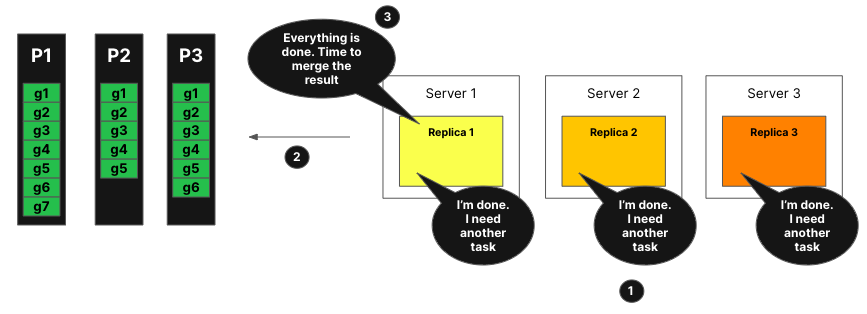
Все реплики теперь завершили обработку своей задачи. Они запрашивают дополнительные задачи.
Координатор, используя объявления, проверяет, какие задачи еще нужно обработать, но нет оставшихся задач.
Координатор сообщает репликам, что все было обработано. Он теперь объединит все агрегируемые состояния и ответит на запрос.
Управление локальностью кэша
Последней потенциальной проблемой является то, как мы обрабатываем локальность кэша. Если запрос выполняется несколько раз, как мы можем гарантировать, что одна и та же задача будет направлена на одну и ту же реплику? В предыдущем примере у нас были следующие назначенные задачи:
| Реплика 1 | Реплика 2 | Реплика 3 | |
|---|---|---|---|
| Часть 1 | g1, g6, g7 | g2, g4, g5 | g3 |
| Часть 2 | g1 | g2, g4, g5 | g3 |
| Часть 3 | g1, g6 | g2, g4, g5 | g3 |
Чтобы гарантировать, что одни и те же задачи назначаются одним и тем же репликам и могут извлечь выгоду из кэша, выполняется две вещи. Вычисляется хэш части + набор гранул (задача). Применяется модуль количества реплик для назначения задачи.
На бумаге это звучит хорошо, но на практике внезапная нагрузка на одну реплику или ухудшение сети могут вызвать задержку на конце, если одна и та же реплика постоянно используется для выполнения определенных задач. Если max_parallel_replicas меньше числа реплик, то случайные реплики выбираются для выполнения запроса.
Кража задач
Если какая-то реплика обрабатывает задачи медленнее других, другие реплики попытаются "похитить" задачи, которые принципиально принадлежат этой реплике по хэшу, чтобы уменьшить задержку в конце.
Ограничения
У этой функции есть известные ограничения, основные из которых документированы в этом разделе.
Если вы нашли проблему, которая не входит в перечисленные ограничения, и подозреваете, что параллельная реплика является причиной, пожалуйста, создайте проблему на GitHub с помощью метки comp-parallel-replicas.
| Ограничение | Описание |
|---|---|
| Сложные запросы | В настоящее время параллельная реплика работает довольно хорошо для простых запросов. Сложные слои, такие как CTE, подзапросы, JOIN, сложные запросы и т.д., могут иметь негативное влияние на производительность запроса. |
| Маленькие запросы | Если вы выполняете запрос, который не обрабатывает много строк, его выполнение на нескольких репликах может не дать лучшего времени производительности, поскольку время сети для координации между репликами может привести к дополнительным циклам в выполнении запроса. Вы можете ограничить эти проблемы, используя настройку: parallel_replicas_min_number_of_rows_per_replica. |
| Параллельные реплики отключены с FINAL | |
| Данные с высокой кардинальностью и сложная агрегация | Высококардинальная агрегация, которая требует отправки большого количества данных, может значительно замедлить ваши запросы. |
| Совместимость с новым анализатором | Новый анализатор может значительно замедлить или ускорить выполнение запросов в конкретных сценариях. |
Настройки, связанные с параллельными репликами
| Настройка | Описание |
|---|---|
enable_parallel_replicas | 0: отключено1: включено 2: Принудительно использовать параллельную реплику, выдаст исключение, если не используется. |
cluster_for_parallel_replicas | Имя кластера, которое будет использоваться для параллельной репликации; если вы используете ClickHouse Cloud, используйте default. |
max_parallel_replicas | Максимальное количество реплик, которые будут использоваться для выполнения запроса на нескольких репликах, если указано число меньшее, чем количество реплик в кластере, узлы будут выбраны случайным образом. Это значение также можно переопределить для учета горизонтального масштабирования. |
parallel_replicas_min_number_of_rows_per_replica | Помогает ограничить количество используемых реплик в зависимости от количества строк, которые необходимо обработать, количество используемых реплик определяется по формуле: предполагаемые строки для чтения / минимальное количество строк на реплику. |
allow_experimental_analyzer | 0: использовать старый анализатор1: использовать новый анализатор. Поведение параллельных реплик может измениться в зависимости от используемого анализатора. |
Исследование проблем с параллельными репликами
Вы можете проверить, какие настройки используются для каждого запроса в таблице
system.query_log. Вы также можете
посмотреть таблицу system.events
чтобы увидеть все события, которые произошли на сервере, и вы можете использовать
функцию таблицы clusterAllReplicas для просмотра таблиц на всех репликах
(если вы пользователь облака, используйте default).
Ответ
Таблица system.text_log также
содержит информацию о выполнении запросов с использованием параллельных реплик:
Ответ
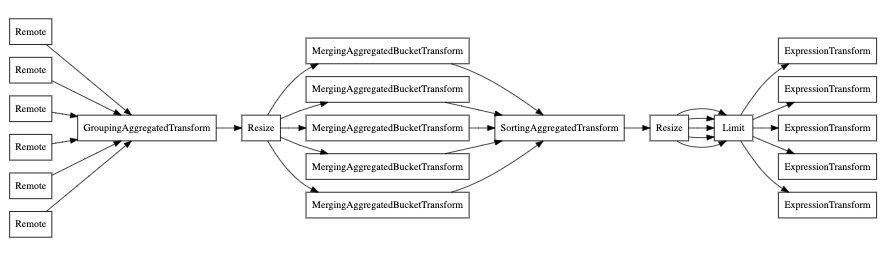
Наконец, вы также можете использовать EXPLAIN PIPELINE. Это подчеркивает, как ClickHouse
будет выполнять запрос и какие ресурсы будут использованы для
выполнения запроса. Давайте возьмем следующий запрос в качестве примера:
Давайте посмотрим на конвейер запроса без параллельных реплик:
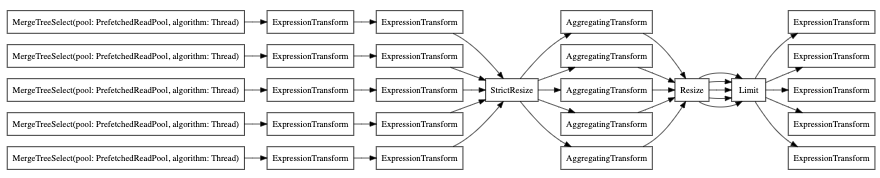
А теперь с параллельной репликой: